-
[Python] Pandas 선택하기Python/pandas 2022. 10. 13. 14:03728x90반응형
목차
선택 과 설정을 위한 표준 파이썬 / NumPy 식은 직관적이고 대화형 작업에 유용하지만, 프로덕션 코드의 경우 최적화된 Pandas 데이터 엑세스 방법인 DataFrame.at(), DataFrame.iat(), DataFrame.loc() 그리고 DataFrame.iloc()를 추천한다.
Getting
열을 하나만 선택하면 df.A와 동일한 Series가 생성된다.
df["A"]
[]를 통하면, 다음과 같이 분할한다.
df[0:3]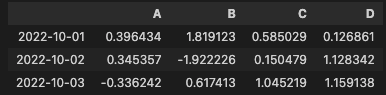
df["20221002" : "20221005"]
Selection by label
DataFrame.loc() 또는 DataFrame.at()을 사용한 레이블 별 선택을 참조
레이블을 사용하여 횡단면을 가져오는 경우
df.loc[dates[0]]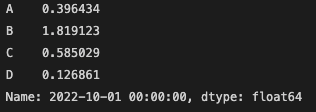
레이블별 다중 축 선택
df.loc[:, ["A", "B"]]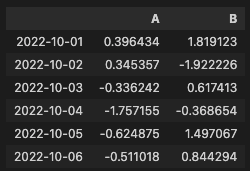
레이블 슬라이싱을 표시하면 두 끝점이 모두 포함된다.
df.loc["20221002":"20221004", ["A", "B"]]
반한된 객체의 치수 감소
df.loc["20221002", ["A", "B"]]
스칼라 값을 가져오는 경우
df.loc[dates[0], "A"]
스칼라에 빠르게 액세스하는 경우(위의 방법과 동일)
df.at[dates[0], "A"]
Selection by position
DataFrame.iloc() 또는 DataFrame.at()를 사용하여 위치별 선택을 참조.
전달된 정수의 위치를 통해 선택
df.iloc[1]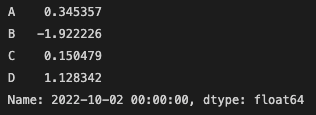
정수 슬라이스에 따라 NumPy / Python과 유사하게 작동된다.
df.iloc[3:5, 0:2]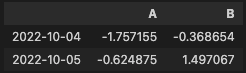
NumPy / Python 스타일과 유사한 정수 위치 목록
df.iloc[[1, 2, 4], [0, 2] ]
행을 명시적으로 자르는 경우
df.iloc[1:3, :]
열을 명시적으로 자르는 경우
df.iloc[:, 1:3]
값을 명시적으로 가져오는 경우
df.iloc[1,1]
스칼라에 빠르게 엑세스 하는 경우(위 방법과 동일)
df.iat[1,1]
Boolean indexing
단일 열의 값을 사용하여 데이터 선택
df[df["A"] > 0]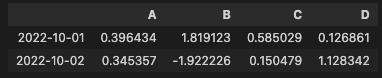
관계식이 충족되는 데이터 프레임에서 값 선택
df[df > 0]
필터링에 isin() 메소드 사용
df2 = df.copy() df2["E"] = ["one", "one", "two", "three", "four", "three"] df2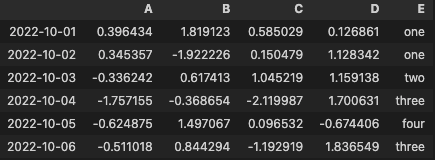
df2[df2["E"].isin(["two", "four"])]
Setting
새로운 열을 설정하면 데이터가 인덱스별로 자동으로 정렬.
s1 = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range("20130102", periods=6)) s1
레이블별 값 설정
df["F"] = s1 df.at[dates[0], "A"] = 0위치별 값 설정
df.iat[0, 1] = 0NumPy 배열로 할당하여 설정
df.loc[:, "D"] = np.array([5] * len(df))위의 설정 작업의 결과
df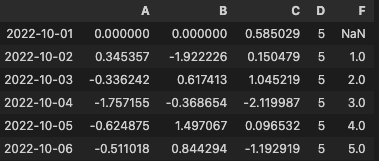
where 연산(설정 포함)
df2 = df.copy() df2[df2 > 0] = -df2 df2 반응형
반응형'Python > pandas' 카테고리의 다른 글
[Python] Pandas Merge (0) 2022.10.13 [Python] Pandas Operations (0) 2022.10.13 [Python] Pandas 결측치 (1) 2022.10.13 [Python] Pandas 데이터보기 (1) 2022.10.11 [Python] Pandas 객체 생성 (0) 2022.10.11